
这篇文章继续给大家来讲解seo基础知识的内容,robots.txt的撰写。
估计大家在用WordPress建站的时候,都没有注意过这个文件,因为正常其实不需要管robots.txt文件里面写了什么内容,WordPress默认的都是可以让搜索引擎抓取网站所有内容的,所以我们正常也就忽略掉这个文件了。
但是如果你的网站有一些内容不希望搜索引擎抓取的话,就可以在robots.txt文件里面,禁止搜索引擎抓取,下面猎者出海就跟大家来聊聊robots.txt是什么以及网站robots正确写法。
本文目录
robots.txt是什么?
Robots.txt是网站根目录下的一个纯文本文件,你在你的网站根目录里面会看到有一个Robots.txt的文件,

同时你也可以直接通过输入网址,打开你的Robots.txt文件,查看里面的内容,一般网址都是:
https://www.liezhe.com/robots.txt
打开后,是一个文本文档,如下图所示:
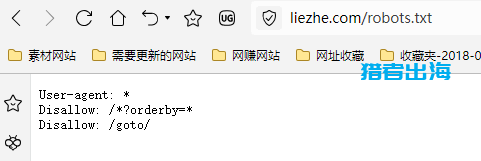
它用来告诉搜索引擎爬虫(如 Googlebot、Bingbot)我们网站哪些页面可以抓取,哪些页面是禁止抓取的。
一般来说,新站刚把sitemap网站地图提交给搜索引擎的时候,搜索引擎蜘蛛会优先抓取网站robots.txt文件,查看一下网站有哪些内容是禁止抓取的,然后再按照我们网站robots.txt文件的内容,进行网站内容抓取。
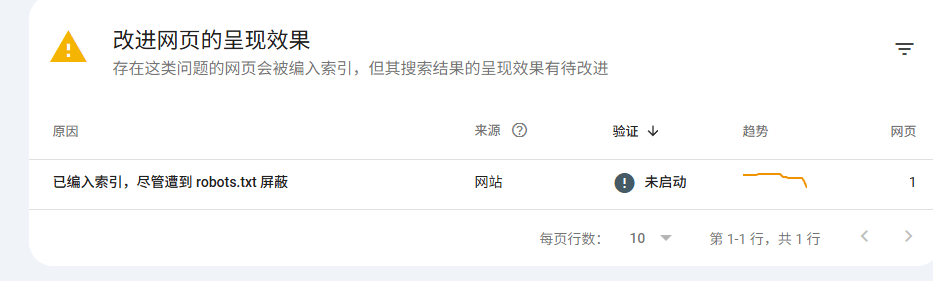
当然,robots.txt属于是“爬取控制文件”,并不是强制性的性的,所以你会发现,有一些时候,即使你在robots.txt文件禁止抓取你的网站一些内容,但是可能搜索引擎依然还是会抓取。
下图可以看到,尽管我在网站robots.txt文件里面已经屏蔽了,但是google搜索引擎还是索引了这个页面。
robots.txt的作用
上面已经跟大家说了,robots.txt文件主要是为了告诉搜索引擎要抓取哪些页面或者不能抓取哪些页面。
那么robots.txt的主要作用到底是什么呢,一共有如下几个:
1.允许搜索引擎抓取有价值页面
可以帮助网站快速收录,因为如果蜘蛛爬行大量的无效页面会浪费搜索引擎抓取预算,导致其他有价值的页面并未被抓取或者抓取时间比较慢。
2.阻止搜索引擎抓取无必要页面
有的页面可能是WordPress主题自动生成的一些重复页面或者垃圾页面,而且数量可能会非常庞大,这些页面本身也不会被搜索引擎收录,反而会浪费大量的抓取预算,如下图所示:

这些以orderby=xxx,为结尾的文件,都是WordPress主题功能自动生成的页面,例如:按照阅读量排名、按照时间排名等。
这些页面本身就是不需要搜索引擎去收录的,而且即使是收录了也没有任何的用处,即拿不到关键词排名,又提升不了网站权重,所以必须要在robots.txt里面屏蔽搜索引擎蜘蛛抓取。
还有例如,不能让搜索引擎抓取的页面,像网站后台、脚本文件这些,包括我们一些需要隐藏的页面或者是需要特定权限才能访问的页面。
例如,猎者出海的网站里面有个板块,只有独立站私教培训的学员才能访问,这个板块是被隐藏的,并且是需要特定权限才能访问的,所以我要在robots.txt里面屏蔽搜索引擎抓取这个板块里面的所有内容。
robots.txt基本写法
robots.txt的基本写法如下:
User-agent: [爬虫名称]
如:googlebot、bingbot、baiduspider等,你要屏蔽哪个搜索引擎的抓取,就可以写哪个搜索引擎,要是屏蔽所有搜索引擎,就用*号来替代,就是代表所有搜索引擎蜘蛛。
Disallow: [不允许访问的路径]
Allow: [允许访问的路径]
Sitemap: [站点地图地址]
大家可以看一下猎者出海网站的robots.txt:
User-agent: *
Disallow: /?orderby=
Disallow: /goto/
第一个Disallow:禁止搜索引擎抓取URL中包含参数 ?orderby= 的所有页面,例如上面大家看到的:
https://www.liezhe.com/tag/seo软件/?orderby=date(按照日期给文章排序的tag标签列表页)
https://www.liezhe.com/tag/seo软件/?orderby=views(按照阅读量给文章排序的tag标签列表页)
第二个Disallow:禁止爬虫访问以 /goto/ 开头的路径
这个是猎者出海之前网站装了一个WordPress插件,可以把外部链接,转化为内部链接,但是因为是跳转链接,所以我设置的都是含有/goto/路径的URL,这些URL,会被google搜索引擎当成是网站内部链接,从而被抓取和收录,所以我在robots.txt里面直接给屏蔽了。
目的就是告诉搜索引擎这些中转跳转页面没必要抓取,也不要浪费爬取配额。
WordPress博客robots.txt常规写法
下面是WordPress博客一般默认的robots.txt写法(如果你的网站没有需要屏蔽的页面):
User-agent: *
Disallow: /wp-admin/
Allow: /wp-admin/admin-ajax.php
Sitemap: https://www.example.com/sitemap.xml
解释:
User-agent: * → 适用于所有搜索引擎爬虫
Disallow: /wp-admin/ → 禁止爬取后台目录
Allow: /wp-admin/admin-ajax.php → 允许必要文件
Sitemap: → 指定站点地图位置,帮助爬虫发现页面
如何编辑robots.txt文件
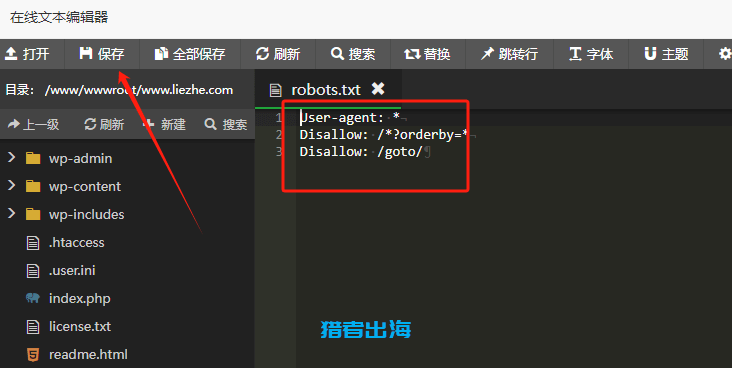
编辑robots.txt文件非常简单,直接在宝塔里面编辑即可,按照下面步骤来操作:
首先,进入到宝塔,网站根目录,找到我们的robots.txt文件,如果没有的话,可以直接创建一个robots.txt
然后直接双击robots.txt,弹出编辑页面
在里面输入内容,然后点击保存即可。
robots与noindex的区别
| 对比项目 | Robots.txt | Noindex 标签 |
|---|---|---|
| 定义 | Robots.txt是放在网站根目录下的文件,用于告诉搜索引擎“哪些页面或目录可以爬取,哪些不能爬取”。 | Noindex 是在网页HTML中添加的 <meta> 标签,告诉搜索引擎“即使抓取了该页面,也不要将它收录到搜索结果中”。 |
| 控制对象 | 控制的是 爬取(Crawl) 权限。 | 控制的是 收录(Index) 权限。 |
| 使用位置 | 放在网站根目录下,路径为:https://www.liezhe.com/robots.txt |
写在网页的 <head> 区域中,示例:<meta name="robots" content="noindex, nofollow"> |
| 主要作用 | 告诉搜索引擎哪些页面 不应被抓取;但如果其他网站有链接指向该页面,搜索引擎仍可能知道它的存在。 | 允许搜索引擎抓取页面,但告知其 不要将该页面显示在搜索结果中。 |
| 是否可抓取内容 | 不可抓取(搜索引擎不会访问页面内容) | 可抓取(搜索引擎会读取内容,但不收录) |
| 是否可能出现在搜索结果中 | 有可能:如果其他页面有指向该URL的外部链接,搜索引擎可能仍显示一个“空白标题的结果”。 | 不会出现在搜索结果中(完全被排除收录)。 |
| 典型应用场景 |
|
|
| 是否适用于动态URL | 支持路径和参数匹配(如 Disallow: /?orderby=) |
页面级控制,可以精确到单个页面 |
| 优先级 | 优先级更高,如果在robots.txt中禁止抓取,搜索引擎将无法访问页面,自然也无法看到noindex标签。 | 依赖于搜索引擎能抓取页面;如果被robots.txt屏蔽,noindex标签将无法生效。 |
| 配合建议 | 用于屏蔽无价值的路径或参数页面,节省抓取预算。 | 用于需要访问但不希望出现在搜索结果中的页面。 |
| 实战建议 | 对无意义页面、后台目录、重复页使用 Disallow。 |
对低质量内容页、隐私政策、用户协议使用 noindex。 |
发表评论